前言
嗯,没错,又是一篇「如何打造一个 XXX 的博客」的文章。这里的 XXX 是「基于 React 的 SEO 友好」。其中的 SEO 既是 Search engine optimization,搜索引擎优化。
什么?React?你不是 Angular 的教徒吗?怎么叛变到 React 了呢?
嗯,这就说来话长了。
Angular 还未达到 SEO-friendly 的程度
单页应用一直有一个令人诟病的问题就是就是其对搜索引擎不友好。
究其原因,就是单页应用核心就是 JavaScript 应用,而一般的搜索引擎都只在乎你页面的 HTML 而对于其中的 JavaScript 是不会执行的。
虽然 Google 曾经表示会抓取单页应用(对 Ajax 的结果进行缓存),但是现在已经表示已经不再支持了。
难道单页应用就是不能实现 SEO 吗?并不是,还是可以通过一种名叫 Server-side rendering (服务器端预渲染)的方式来实现的。
Angular 的 Server-side Rendering API 叫 Angular Univeral API,并且也已经整合进了 Angular 4。
虽然前景是好的,但是目前支持的 Angular Universal 的库少之又少,难怕是 Angular 官方的 Angular Material 也尚未支持。
而相比之下,React 的 Server-side Rendering API:ReactDOMServer.renderToString() 则适用程度大了很多,至少我目前还没有发现不支持的库。
当然也有可能是 React 的 API 实现的非常简单,生成 HTML 时,只调用了
constructor()、componentWillMount()、render()和componentDidMount()几个方法。
所以我叛教了。:)
react-snapshot & react-helmet
想调用 React 的 Server-side Rendering 的 API 的话,最简单的方法是使用 react-snapshot。
它和 creat-react-app(一个类似 Angular Cli 的命令行工具)整合得很好,只需要将 render() 替换成 React-Snaport 提供的 render() 即可。它会在 Developer Mode 的时候调用 Render.render() 和之前一样;在 Production Mode 的时候调用 ReactDomServer.toSting()。
在运行 react-scripts build 后再运行 react-snapshot,就会开启一个爬虫,将所以的页面遍历一遍后,导出至 HTML。
运行结果:
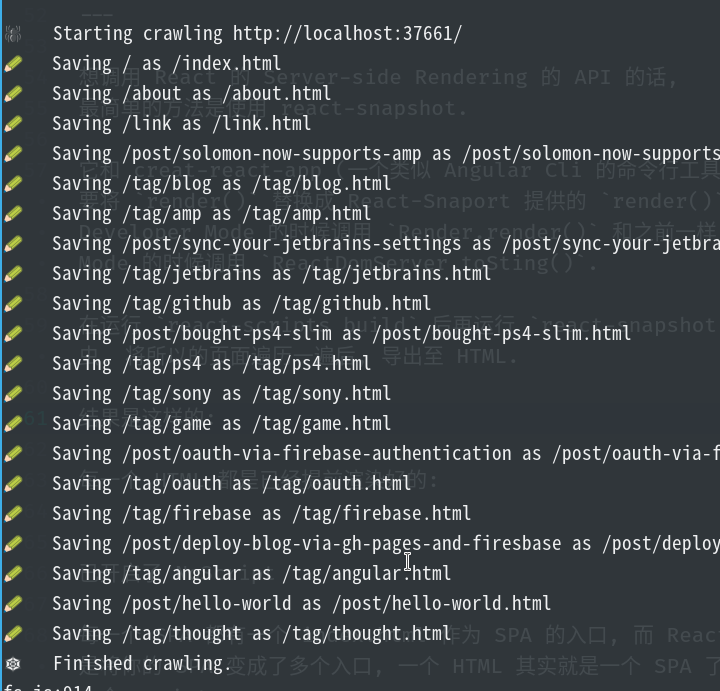
使用 w3m 访问 About 页面的结果:
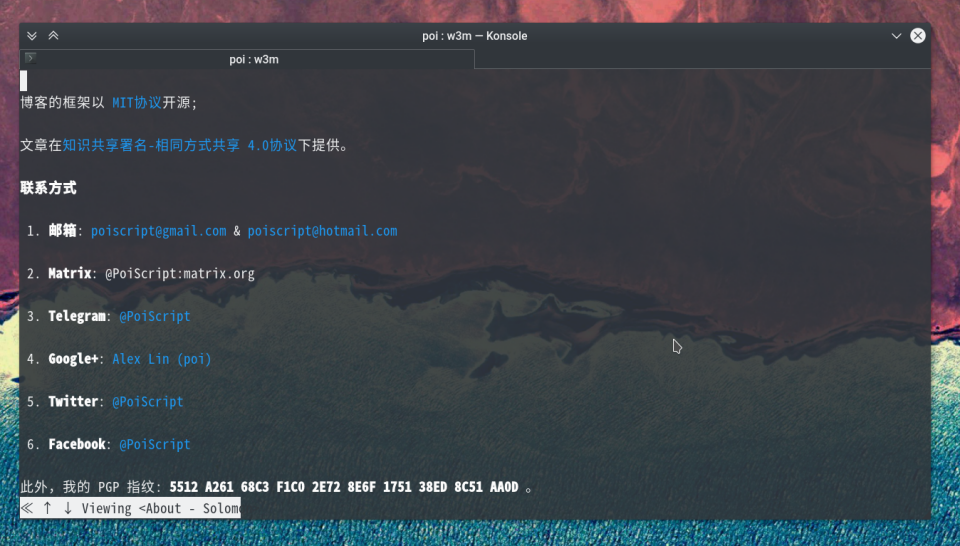
同时也保留了单页应用不需要重复加载的优点:
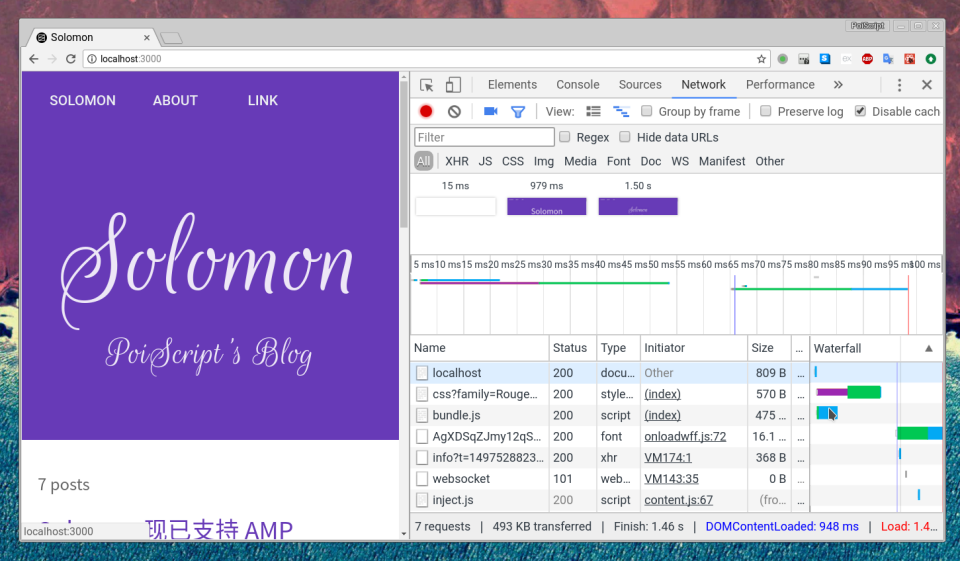
原理是什么?每一个单页应用都有一个
index.html作为的入口。而使用了 react-snapshot 之后你的单页应用相当于有了同时多个不同入口,或者说你同时拥有了复数多个功能相同的单页应用。
react-snapshot 目前还有一个问题(对我来说),它会将路径 其实不用那么复杂,只需要在路径后面加上一个 /path/to/page 保存为 /path/to/page.html,但是并不是所有的服务器都可以识别,例如 Python 的 SimpleHTTPServer 就不行。所以我写了一个小脚本,将保存好的 /path/to/page.html 重命名为 /path/to/page/index.html。我给 react-snapshot推了一个 Pull Request,增加将页面保留保存为 /path/to/page/index.html 的形式,希望可以被合并,这样就能省去这一步了。/,即可生成 index.html 的文件。
如果说 react-snapshot 让你的单页应用里的 body 标签搜索引擎可见的话,那 react-helmet 就可以让你的单页应里的 head 标签能被搜索引擎爬到了。
而 head 中的 meta 标签更是 SEO 的关键之一,通过它我们可以主动给爬虫提供重要的信息,例如文章的作者,发布时间等。
更进一步
嗯,经过 react-snapshot 和 react-helmet 处理之后,已经能够完全满足 SEO 的需求了。
其实文章写到这里,除了一些关于 Angular 的吐槽和 react-snapshot 的小修改的话,和 Medium 上的这篇文章其实没什么区别。
但是还有一些缺点,在说之前,先说一下为什么单页引用可以提高网页的响应速度,减少资源的加载次数。
因为单页应用虽然在第一个页面的时候,需要加载更多的内容(毕竟还要加载 JavaScript)但是在访问第二个,第三个页面的时候,则不需要请求任何的资源,因为它们是由你的浏览器动态生成的。
假设你访问一个传统的静态网页,每访问一个页面,你可能只需要 60 的数据量,但是你每访问一个页面都需要 60 的数据量。而访问一个单页应用,你需要 200 的数据量 —— 但是从头到尾都只需要这 200 的数据量。
所以使用 react-snapshot 之后,可以达到切换页面不需要重新载入文字的原因是,它其实是将你的所有文字都写入了 JavaScript。
以上面的 Medium 那篇文章中给的 Demo:https://yadg.surge.sh/ 为例,/ 和 /about 的文字都写进了 JavaScript 里,所以才能做到流畅的切换(因为全部帮都下载来了………):
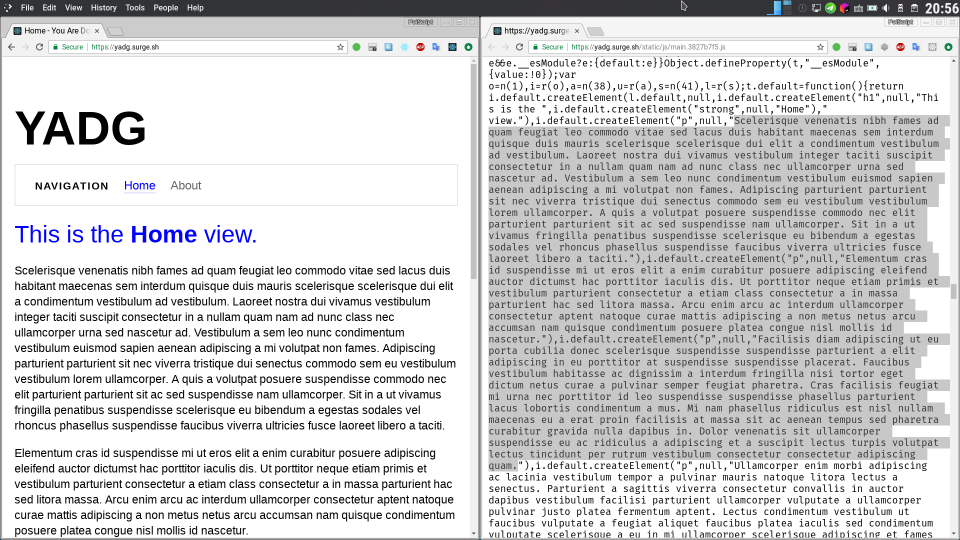
所以假设你有上百篇文章的话,造成的结果就是用户需要在加载的完全部的文章之后才可以正常使用你的博客(在没有加载完剩余的文章之前,用户只能盯着当前的页面什么都做不了)。
如果访问一个单页应用需要 2000 的数据量的话,那还值得吗?
虽然目前来说也就我的博客也就几篇文章,远远达不到 2000 数据量的程度,不过随着时间的增长,这个问题只会越来越明显。
所以我做了一个改进:在 React 中使用 XHR(XML HTTP Request) 获取文章,而不是用上面 Medium 里用 Component 的形式。这样就不需要全部写进 JavaScript 里了。
等一下,如果使用 XHR 的话,在调 render() 的时候,是不会含有文字的:因为 XHR 请求是异步,而 React 中的 setState 函数也是异步的。
没错,就是空标签。那么说好的 SEO 呢?很简单,把生成的 HTML 里的空标签替换成我们的文章即可。:)
提示:直接替换生成的 HTML 文件是一个危险的行为,最好替换普通的标签,不要替换 React Component 生成的标签。
因为如果随意替换的话,可以会丢掉带有额外属性(例如:
data-reactid)的标签。其中data-reactid是 React 给每一个 Component 的一个唯一的标识符,如果缺少了其中的某一个的话,会导致 React 停止工作。
后语
在经过上述的步骤之后,我们的博客将拥有一下特性:
基于 React 模型;
博客中的每一个链接都是可以直接打开,而不需要将路由重写至
index.html。而且每一个页面都有 Server-side rendering,可以被搜索引擎爬到,哪怕是不支持 JavaScript 的纯文本浏览器(例如 w3m)也可以直接访问,而不会显示那个臭名昭著的 "Loading";:)在打开一个页面之后,除非是查看一篇新的文章,否则,不需要再加载任何的资源。而查看一篇新的文章时,也只需要加载文章本身的 HTML;而其他组件和 CSS 都不需要重新加载。
这是我想到的目前来说,最完美的单页应用的 SEO 的解决方案。
有什么疑问的话,可以查看 Solomon 中 react 的源码,当然也欢迎向我提问。
算上这篇文章,我的博客里几乎半数以上都是「如何打造一个 XXX 的博客」的文章了 :(,一点都不技术 poi。
接下来我大概会继续我的 Rust 学习之旅,然后…等到我做了些真正有趣的东西再和大家分享吧。